
Spring 解析默认标签~[TOC]
从上一篇笔记可以看出,在容器注册 bean 信息的时候,做了很多解析操作,而 xml 文件中包含了很多标签、属性,例如 bean 、 import 标签, meta 、look-up 和 replace等子元素属性。
上一篇主要介绍 Spring 容器的基础结构,没有细说这些标签是如何解析的。
所以本篇是来进行补坑的,介绍这些标签在代码中是如何识别和解析的~
本篇笔记的结构大致如下:
- 介绍概念
- 展示
demo代码,如何使用 - 结合源码分析
- 聊聊天和思考
再次说下,下载项目看完整注释,跟着源码一起分析~
在 Spring 中,标签有两种,默认和自定义:
默认标签
这是我们最常使用到的标签类型了,像我们一开始写的<bean id="book" class="domain.SimpleBook"/>,它属于默认标签,除了这个标签外,还有其它四种标签(import、alias、bean、beans)自定义标签
自定义标签的用途,是为了给系统提供可配置化支持,例如事务标签<tx:annotation-driven />,它是Spring的自定义标签,通过继承NamespaceHandler来完成自定义命名空间的解析。
先看源码是如何区分这两者:
|
|
可以看到,在代码中,关键方法是 delegate.isDefaultNamespace(ele) 进行判断,识别扫描到的元素属于哪种标签。
找到命名空间 NamespaceURI 变量,如果是 http://www.springframework.org/schema/beans,表示它是默认标签,然后进行默认标签的元素解析,否者使用自定义标签解析。
本篇笔记主要记录的是默认标签的解析,下来开始正式介绍~
默认标签解析
parseDefaultElement 方法用来解析默认标签,跟踪下去,发现对四种标签做了不同的处理,其中 bean 标签的解析最为艰难(对比其它三种),所以我们将 bean 标签解析吃透的话,其它三种标签的解析也能更好的熟悉。
入口方法:
|
|
Bean 标签解析入口
定位到上面第三个方法 processBeanDefinition(ele, delegate):
|
|
上一篇笔记只是简单描述这个方法的功能:将 xml 中配置的属性对应到 document 对象中,然后进行注册,下面来完整描述这个方法的处理流程:
- 创建实例
bdHolder:首先委托BeanDefinitionParserDelegate类的parseBeanDefinitionElement方法进行元素解析,经过解析后,bdHolder实例已经包含刚才我们在配置文件中设定的各种属性,例如class、id、name、alias等属性。 - 对实例
bdHolder进行装饰:在这个步骤中,其实是扫描默认标签下的自定义标签,对这些自定义标签进行元素解析,设定自定义属性。 - 注册
bdHolder信息:解析完成了,需要往容器的beanDefinitionMap注册表注册bean信息,注册操作委托给了BeanDefinitionReaderUtils.registerBeanDefinition,通过工具类完成信息注册。 - 发送通知事件:通知相关监听器,表示这个
bean已经加载完成
看到这里,同学们应该能看出,Spring 源码的接口和方法设计都很简洁,上层接口描述了该方法要做的事情,然后分解成多个小方法,在小方法中进行逻辑处理,方法可以被复用。
所以看源码除了能了解到框架的实现逻辑,更好的去使用和定位问题,还能够学习到大佬们写代码时的设计模式,融入自己的工作或者学习中~
Bean 标签其它属性的解析过程
在上篇笔记中,已经总结了对属性 id 和 name 的解析,不再赘述,下面讲下对标签其它属性的解析~
首先贴下源码:
org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parseBeanDefinitionElement(org.w3c.dom.Element, java.lang.String, org.springframework.beans.factory.config.BeanDefinition)
|
|
这是一个完整的属性解析过程,包含了 meta、lookup-method、replace-mthod等其它属性解析。
虽然不常用到,但大家多学一个属性,到时遇到适合使用的场景就能进行使用,还有遇到这些属性的问题也不用慌张,我会先讲有什么用,还有如何使用,让大家有个印象~
创建 GenericBeanDefinition
关于 GenericBeanDefinition 的继承体系上一篇已经讲过了,所以这里再简单解释一下这个方法的用途:
createBeanDefinition(className, parent);
从方法名字就能看出,它的用途是创建一个 beanDefinition ,用于承载属性的实例。
在最后一步实例化 GenericBeanDefinition 时,还会判断类加载器是非存在。如果存在的话,使用类加载器所在的 jvm 来加载类对象,否则只是简单记录一下 className。
解析默认 bean 的各种属性
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
这个方法解析的代码实现有点多,所以感兴趣的同学,可以在我上传的代码库中全局搜索找到该方法,里面有对它每个方法用途介绍~
简单描述的话,这个方法是用来解析 <bean> 标签中每一个基础属性,列表如下:
- scope
- abstract
- lazy-init
- autowire
- depends-on
- autowire-candidate
- primary
- init-method
- destroy-method
- factory-method
- factory-bean
可以清晰看到, Spring 完成了对所有 bean 属性的解析,有些经常使用到,例如 autowire 自动织入、init-method 定义初始化调用哪个方法。而有些的话,就需要同学们自己深入学习了解~
解析 meta 属性
先讲下 meta 属性的使用(汗,在没了解前,基本没使用该属性=-=)
|
|
这个元属性不会体现在对象的属性中,而是一个额外的声明,在 parseMetaElements(ele, bd); 方法中进行获取,具体实现是 element 对象的 getAttribute(key),将设定的元属性放入 BeanMetadataAttributeAccessor 对象中
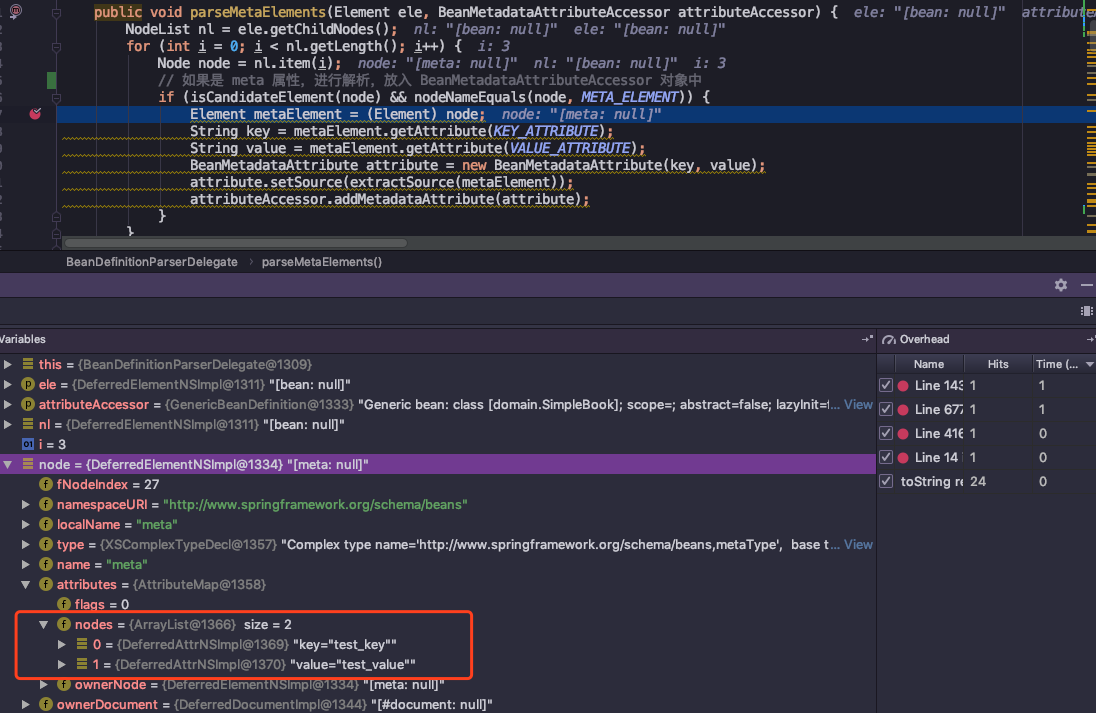
因为代码比较简单,所以通过图片进行说明:
最终属性值是以 key-value 形式保存在链表中 Map<String, Object> attributes,之后使用只需要根据 key 值就能获取到 value 。想到之后在代码设计上,为了扩展性,也可以进行 key-value 形式存储和使用。
解析 lookup-method 属性
这个属性也是不常用,引用书中的描述
通常将它成为获取器注入。获取器注入是一个特殊的方法注入,它是把一个方法声明为返回某种类型的
bean,但实际要返回的bean是在配置文件里面配置的,次方法可用在设计有些可插拔的功能上,解除程序依赖。
代码写的有点多,我贴张图片,介绍一下关键信息:
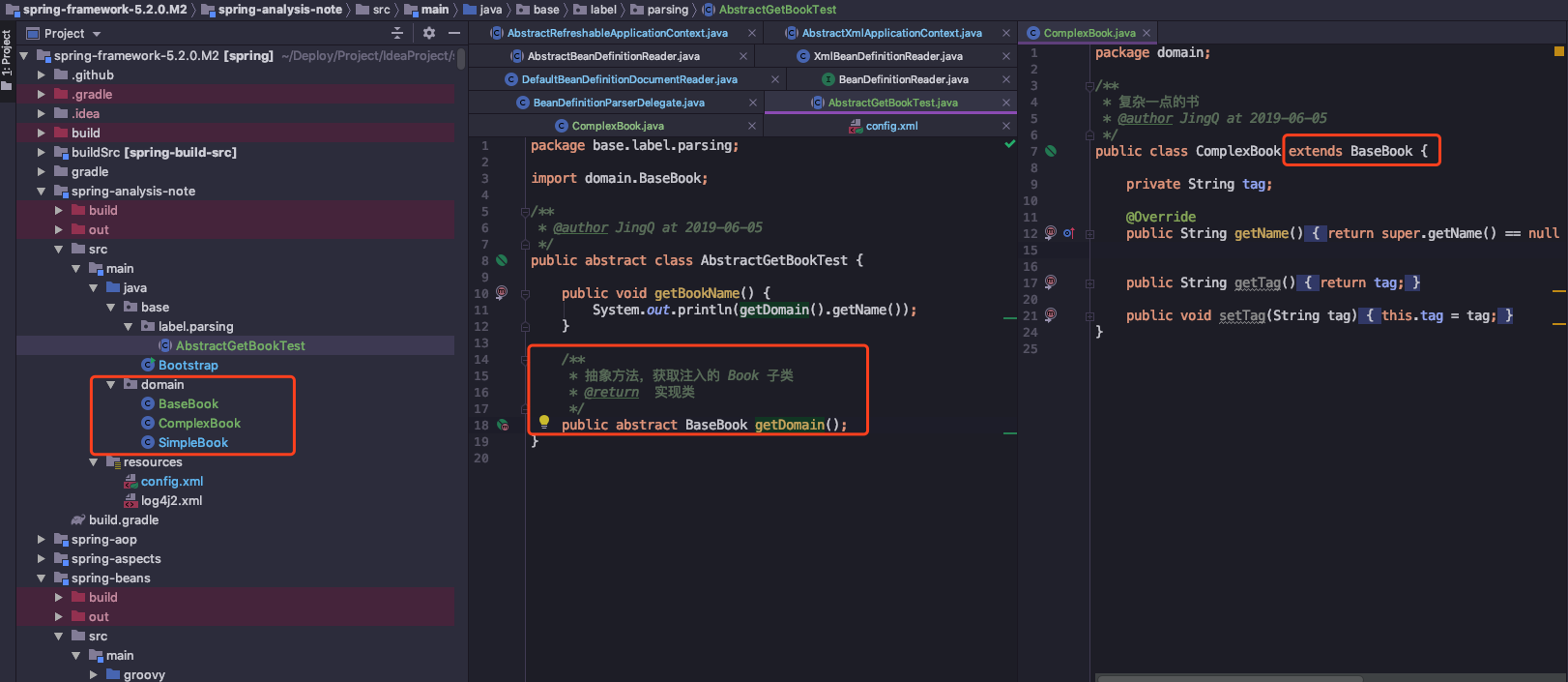
首先我定义了一个基础对象 BaseBook 和两个继承对象 SimpleBook、 ComplexBook,还新建一个抽象类,并且设定了一个方法 getDomain,返回类型是基础对象。
我觉得是因为抽象类无法被实例化,必须要有具体实现类,所以在这个时候,Spring 容器要加载 AbstractGetBookTest 对象,可以用到 <lookup method> 属性,通过注入特定实现类,来完成类的加载。
config.xml
|
|
Spring 会对 bean 指定的 class做动态代理,识别中 name 属性所指定的方法,返回 bean 属性指定的 bean 实例对象。
既然叫做获取器注入,我们可以将 bean="complexBook" 替换一下,换成 bean="simpleBook",这样注入的类就变成了 SimpleBook 对象了,这样只需要修改配置文件就能更换类的注入~
然后代码对 <lookup-method> 解析跟元属性的解析很相近,所以阅读起来也很容易噢
解析 replaced-method 属性
这个方法的用途:可以在运行时用新的方法替换现有的方法。不仅可以动态地替换返回实体 bean,还能动态地更改原有方法的逻辑。
简单来说,就是将某个类定义的方法,在运行时替换成另一个方法,例如明明看到代码中调用的是 A 方法,但实际运行的却是 B 方法。

从图片中看出,输出框打印出我替换后的文案,实现起来也不难,替换者需要实现 org.springframework.beans.factory.support.MethodReplacer 接口,然后重写 reimplement 方法,关键点在配置文件的 <replaced-method> 属性:
|
|
同样的,Spring 会识别这个 replaced-method 元素中的 name 属性所指定的方法,替换成指定 bean 实例对象的 reimplement 方法。
代码解析过程中,将识别到的属性保存到 MethodOverrides 的 Set<MethodOverride> overrides 中,最终将会记录在 AbstractBeanDefinition 的 methodOverrides中。
个人并不推荐这种使用方法,如果常规工作中,业务驱动比较强烈的情况,如果这样写,会导致别人误解这个方法的意图,如果想要调用查询方法,却被动态代理,调用了删除方法,那就导致不必要的 BUG(还好我没遇到哈哈哈)。
解析 constructor-arg 属性
解析构造函数这个属性是很常用的,但同时它的解析也很复杂,下面贴一个实例配置:
|
|
这个配置所实现的功能很简单,为 TestConstructorArg 自动寻找对应的构造函数,然后根据下标 index 为对应的属性注入 value,实现构造函数。
具体解析在这个方法中:
|
|
代码太多也不贴出来啦,感兴趣的同学定位到我写注释的地方详细看下吧~
下面来梳理下解析构造函数代码的流程:
① 配置中指定了 index 属性
- 解析
constructor-arg的子元素 - 使用
ConstructorArgumentValues.ValueHolder(value)类型来封装解析出来的元素(包含typenameindex属性) addIndexedArgumentValue方法,将解析后的value添加到当前BeanDefinition的ConstructorArgumentValues的indexedArgumentValues属性中
① 配置中没有指定了 index 属性
- 解析
constructor-arg的子元素 - 使用
ConstructorArgumentValues.ValueHolder(value)类型来封装解析出来的元素(包含typenameindex属性) addGenericArgumentValue方法,将解析后的value添加到当前BeanDefinition的ConstructorArgumentValues的genericArgumentValues属性中
这两个流程区别点在于,最后解析到的属性信息保存的位置不同,指定下标情况下,保存到 indexedArgumentValues 属性,没有指定下标情况下,将会保存到 genericArgumentValues。
可以看到,这两段代码处理上,第一步和第二部其实是一样的逻辑,存在重复代码的情况,我刚学习和工作时,为了求快,也有很多这种重复类型的代码。
在慢慢学习更多知识和设计模式后,回头看之前写的代码,都有种删掉重写的冲动,所以如果如果在一开始写的时候,就抽出相同处理代码的逻辑,然后进行代码复用,减少代码重复率,让代码更好看一些,这样就以后就不用被别人和自己吐槽了Σ(o゚д゚oノ)
ref value 属性的处理比较简单,所以大家看代码就能了解它是如何解析的,比较难的是子元素处理,例如下面的例子:
|
|
具体解析子元素的方法是:org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parsePropertySubElement(org.w3c.dom.Element, org.springframework.beans.factory.config.BeanDefinition, java.lang.String)
这个方法主要对各种子元素进行解析,包括 idref value array set map 等等子元素的机械,这里不细说,同学们感兴趣继续去跟踪吧~
解析 property 属性
在配件文件中的使用方式:
|
|
这个解析入口方法跟解析构造函数 constructor-arg 的入口方法很像,代码如下:
|
|
这个入口方法提取到 property 所有子元素,然后调用 parsePropertyElement 方法进行处理,最后使用 PropertyValue 进行封装,最后记录在 BeanDefinition 中的 propertyValues 属性中。
经历过上面复杂属性的解析,property 属性的解析就显得比较简单,都是一样的套路,循环遍历元素进行解析,所以熟悉前面的解析逻辑后,看后面的代码就能更快理解~
解析 qualifer 属性
大家更熟悉的应该是 @qualifer 标签吧,它跟 qualifer 属性的用途一样。
在使用 Spring 框架进行类注入的时候,匹配的候选 bean 数目必须有且只有一个,如果找不到一个匹配的 bean 时,容器就会抛出 BeanCreationException 异常。
例如我们定义了一个抽象类 AbstractBook,有两个具体实现类 Book1 和 Book2,如果使用代码:
|
|
这样运行时就会抛出刚才说的错误异常,我们有两种方式来消除歧义:
① 在配置文件中设定 quailfer
通过 qualifier 指定注入 bean 的名称
|
|
② 使用 @Qualifier("beanNeame")
|
|
同样的,代码的解析过程跟前面的套路相近,留给同学们自己去分析吧~
总结
我们来回顾一下通用解析流程:
- 判断元素类型:在每个入口方法中,都有个判断方法
nodeNameEquals(node, XXXX_METHOD_ELEMENT),符合类型的才进行解析 - 解析:解析一个子元素时,大多数情况下看到是
key-value形式的属性对,通过ele.getAttribute(NAME_ATTRIBUTE)等形式进行获取 - 存储:将上一步解析的结果存储
beanDefinition对应属性中
这样一看,是不是感觉清晰一点了,对于源码的分析也没这么害怕了。
这次终于补了前一篇笔记的小坑,介绍了默认标签的解析流程,下一篇笔记介绍一下自定义标签的解析吧,下一篇再会~
传送门:
参考资料
- Spring 源码深度解析 / 郝佳编著. – 北京 : 人民邮电出版社