
大概过程
在测试环境Docker容器中,在跨进程调用服务的时候,A应用通过Dubbo调用B应用的RPC接口,发现B应用接口超时错误,接着通过debug和日志,发现具体耗时的地方在于一句简单SQL执行,但是耗时超过1000ms。
通过查看数据库的进程列表,发现是有死锁锁表了,很多进程状态status处于’sending data’,最后为锁住的表添加索引,并且kill掉阻塞的请求,解除死锁,服务速度恢复正常。
下面记录的是跟祥哥一起的大致排查过程:
通过观察业务代码,确认没有内存溢出或者其它事务问题,于是只能考虑Docker环境的数据库和jvm底层详情了。
使用Druid监控SQL执行状态
通过日志,发现有一句SQL严重超时,一句简单SQL,原本是批量插入多条记录,为了定位问题,测试时Mybatis只插入一条记录,但即便如此,还是耗时10秒

于是打算使用阿里巴巴的数据库连接池Druid进行监控,这篇文章有教如何使用Druid监控SQL执行状态,监控SQL效果如下:
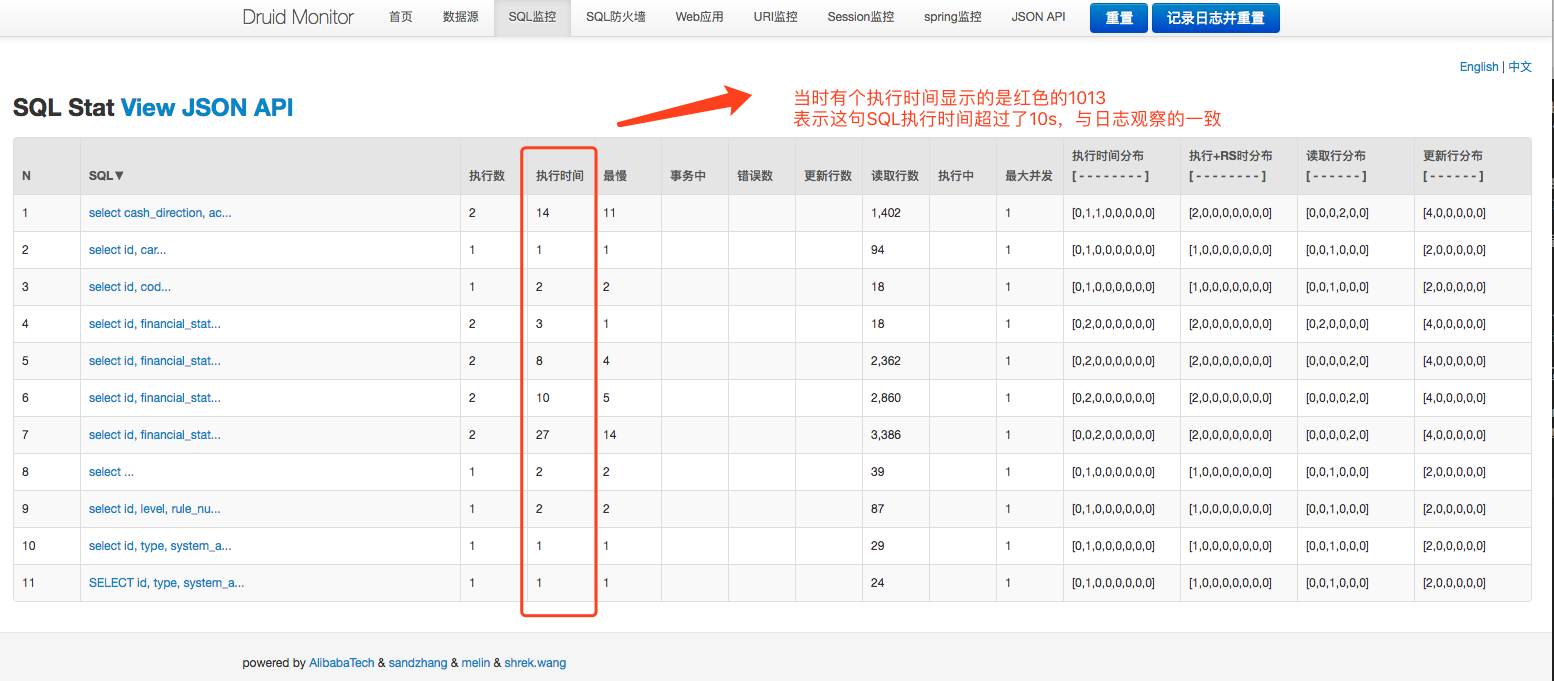
在SQL监控Tab中,可以看到执行SQL的具体情况,包括某条SQL语句执行的时间(平均、最慢)、SQL执行次数、SQL执行出错的次数等
上面显示的是正常情况下,时间单位是ms,正常的SQL一般在10ms之内,数据量大的控制在30ms之内,这样用户的使用体验感才会良好。所以说之前的1000ms,是不可接受的结果。
通过JMC远程监控Tomcat
JMC(java mission control)是jdk自带的一个监控工具,在jdk的bin目录下(java大法好,该目录下有很多实用的工具)。
为了简单,我加了一个tomcat无验证模式:
下面是自己本地调试的截图
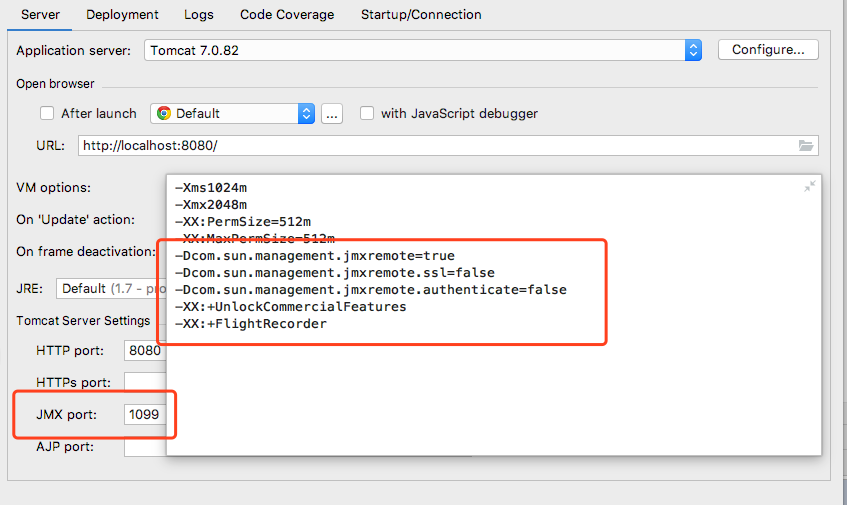
然后打开jmc,创建一个JMX连接,输入对应的ip和JMX端口。接着可以设定一段时间内的飞行监控,监测这一分钟内jvm具体参数
当时调试的时候,发现内存使用、CPU占用率、线程状态也挺正常的,没有发现明显的异常错误,效果如下图:
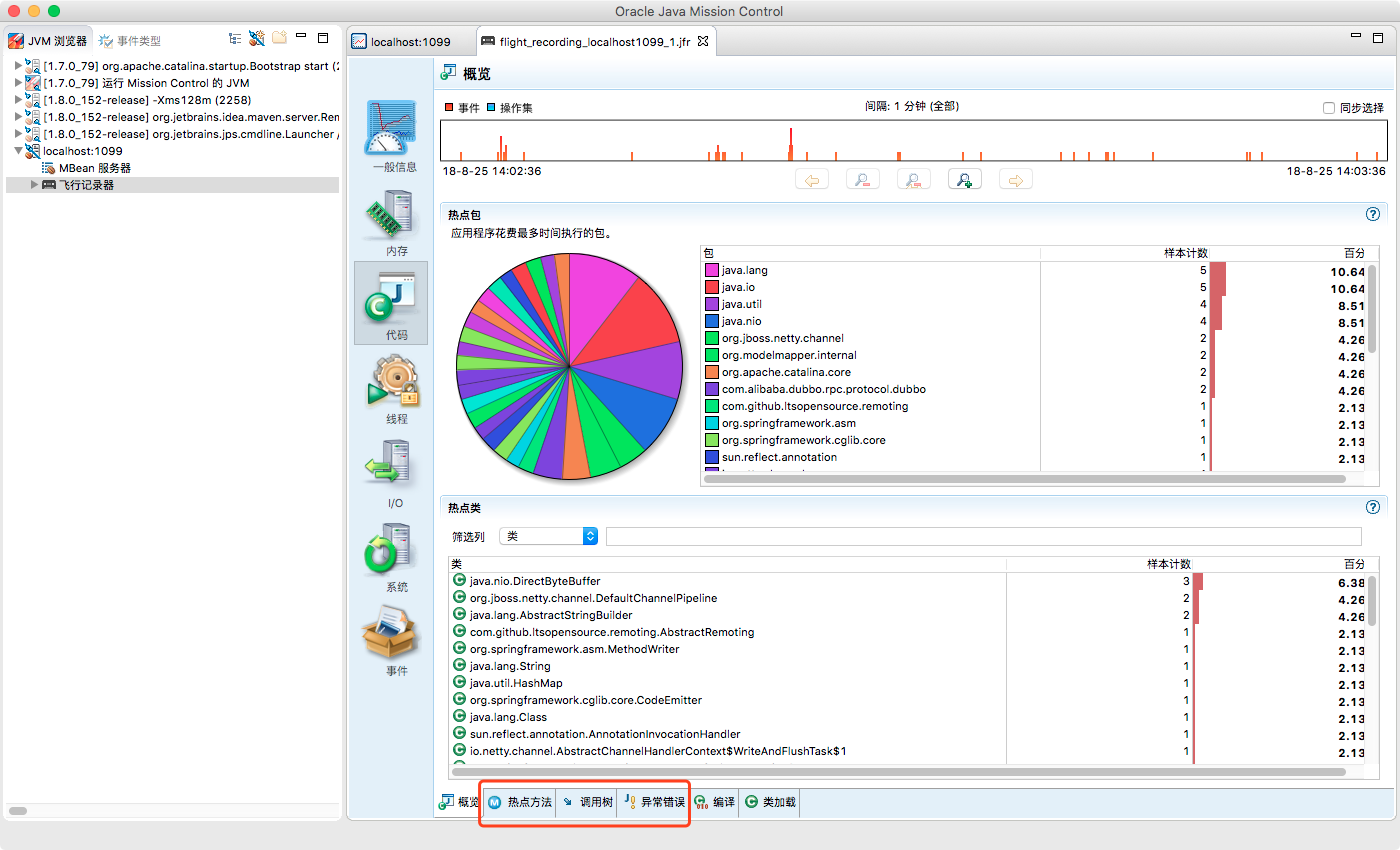
唯一比较耗时的是在代码tab页中,当时发现了大量的I/O,比上图的比例还高,当时大概占了80%,查看调用树,很多循环tcp socket连接,考虑到应用中本来就有很多需要io以及netty也需要tcp连接,所以大概排除了jvm虚拟机的问题,然后就去排查MySQL的问题。
排查MySQL
在了解MySQL锁概念的时候,可以参考这篇文章mysql什么情况下会触发表锁,由于现在使用的比较多的是InnoDB,所以可以着重看看InnoDB锁问题。
直接执行SQL语句
通过DEBUG代码,从mybatis中取出映射后的SQL语句,在MySQL客户款直接执行SQL和Explain查看执行计划,速度都很快,排除了SQL语句的问题。
查看MySQL线程列表
|
|
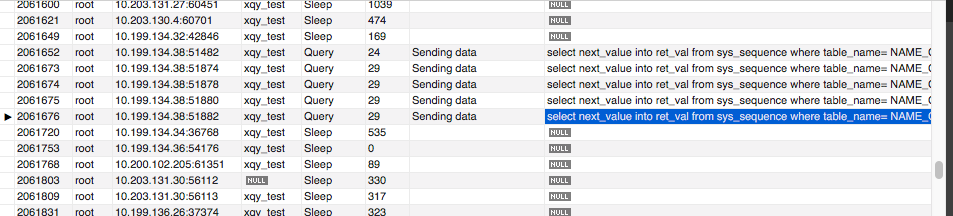
从图中可以看出,有些线程的状态处于sending data,查阅资料:所谓的“Sending data”并不是单纯的发送数据,而是包括“收集 + 发送 数据”。
然后后面一列info显示的是具体信息,是查询用来生成主键ID的函数,之前速度都很快,为啥突然就这么慢呢,于是回过头去查看该函数:
|
|
select for update,给这个表加了排它锁,阻止其它事务取得相同数据集的共享读锁和排他写锁,同时,这个序列表表中,用来检索的字段没有加索引,在InnoDB行锁机制中:

由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键(在我们的场景中,就是查询时用到的table_name),是会出现锁冲突的
所以祥哥了解到其它团队因为查询这个表产生事务问题,造成死锁,这个序列表被锁住了。
由于这个自增序列表每个团队都在使用,所以当时测试环境中,经常有dao层超时错误,最终祥哥将这些阻塞的线程kill掉,为序列表加了索引,解决了问题。
小结
下次遇到MySQL执行耗时的情况,排除了代码问题之后,要去看数据库是否有死锁的情况存在,观察有没有被阻塞的线程,排查被阻塞的线程具体info,定位到具体问题。
欢迎吐槽
具体排查过程是这样,其中还有些细节问题,不清除自己写的思路或者方法有没有错误,如有请轻喷。
对于MySQL锁的机制和底层设计,还是太年轻了,听祥哥意见,去查看官方文档,还有多敲一些命令熟悉一下吧。