HashMap在编程开发中经常使用到,用来存储key-value,但是一直没深入学习它的实现原理,这次学习了记录一下。
HashMap类
|
|
HashMap继承自AbstractMap,AbstractMap是Map接口的骨干实现,AbstractMap中实现了Map中最重要最常用和方法,这样HashMap继承AbstractMap就不需要实现Map的所有方法,让HashMap减少了大量的工作。
HashMap源码定义的变量和常量:
|
|
HashMap的构造函数
|
|
两个很重要的参数:initialCapacity(初始容量)、loadFactor(加载因子),JDK中的是这样解释的:
HashMap 的实例有两个参数影响其性能:初始容量 和 加载因子。
容量 :是哈希表中桶的数量,初始容量只是哈希表在创建时的容量,实际上就是Entry< K,V>[] table的容量
加载因子 :是哈希表在其容量自动增加之前可以达到多满的一种尺度。它衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
HashMap的数据结构
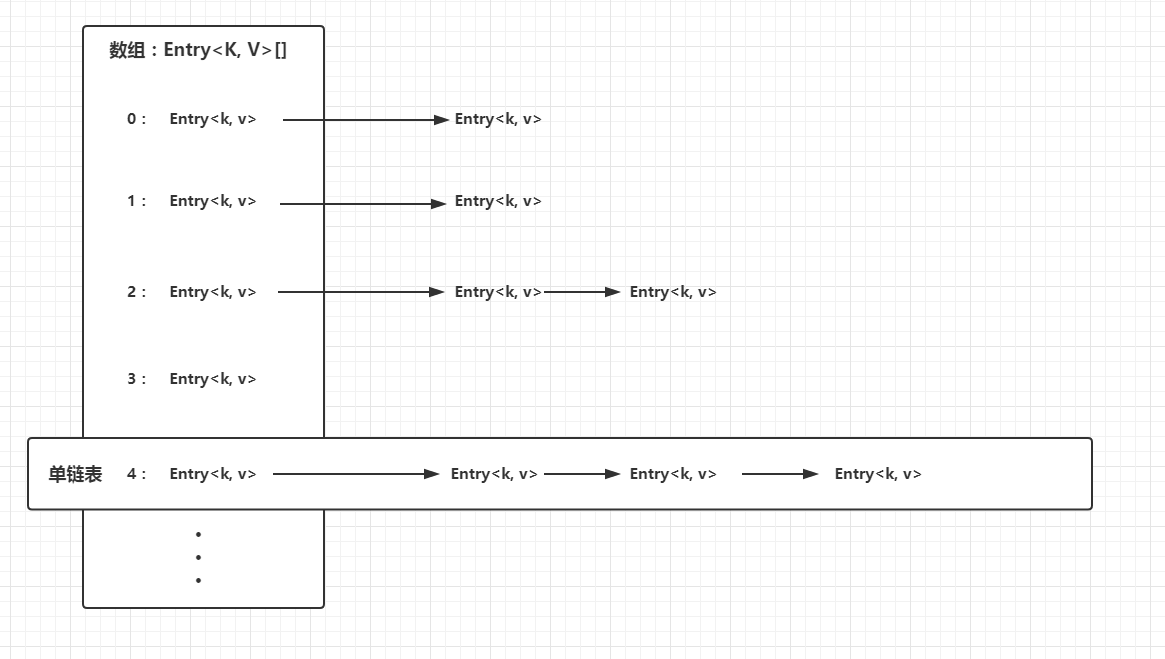
底层实现是用数组和模拟指针实现的链表散列
HashMap构造函数的源码:
初始化函数主要做了三件事情:
- 对传入的初始化容量和加载因子做了校验
- 设置HashMap的极限容量
- 计算出一个离初始化容量最近的2的n次方,用来创建table数组
Table数组的成员Entry
Entry是HashMap的一个内部类,它也是维护着一个key-value映射关系,除了key和value,还有next引用(该引用指向当前table位置的链表),hash值(用来确定每一个Entry链表在table中位置)
HashMap的存储实现Put(K, V)
|
|
存储有两种情况(key为null和非null)
1. key为null的情况:
调用putForNullKey(value):
先找是否有null的键,如果有的话替换旧值,没有的话才进行新增。
2. key不为null:
如果存在key,则在原来链表中更换旧值;如果不存在key,将key-value添加进table数组中。
addEntry(0, null, value, 0):
hash值的计算
|
|
hash算法的作用是为了让hashMap中的元素尽量分散,尽量做到每一个位置上面只有一个元素,当计算出key对应的hash值,马上就能得到该位置上的value就是我们所希望得到的。
其中计算hash值是用异或运算,有可能想到为什么不将hashcode与数组长度做取模运算,取模预算的话得到的位置应该更加均匀。看到的文章说:因为模运算的消耗比较大(可能是计算机最终执行的还是二进制,所以直接用异或会比高级语言更快–大雾,不确定),所以用了异或,消耗更小。
还有一个根据hash值得到table数组下标i的运算indexFor(hash):
下标算法中,先将数组长度-1,然后跟hash值进行&(与)运算,数组长度上面已经计算过了,是2的n次方,先给大家看个图: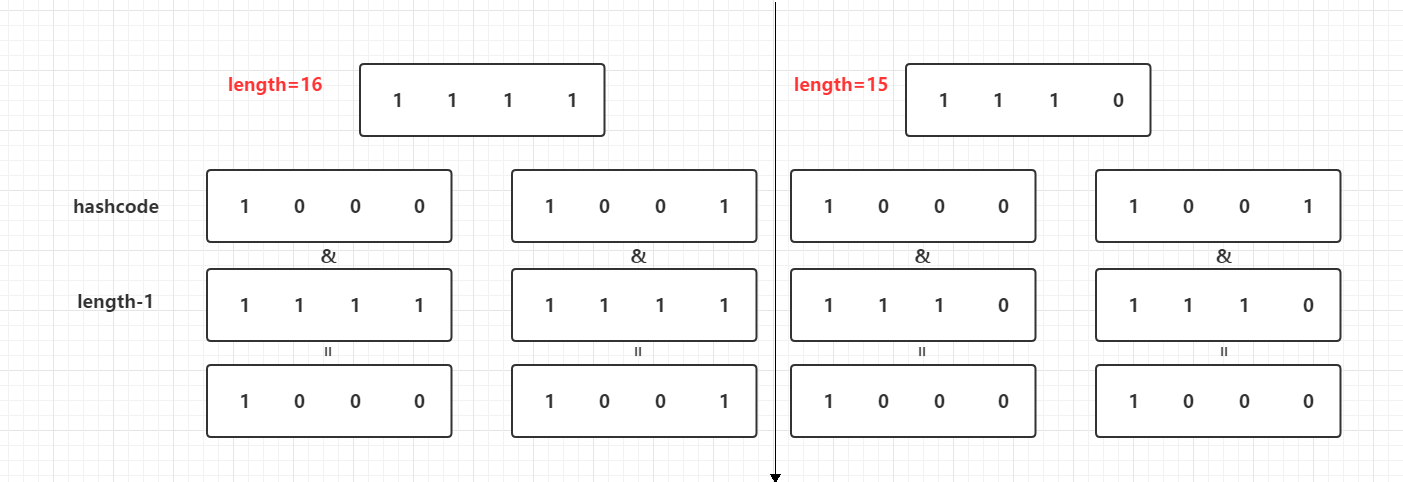
为什么数组的长度要设定在2的n次方呢:
假设一个数组长度为16,另一个数组长度为15,length-1之后换成二进制,刚好两个key计算出来的hash值为8、9,进行与运算,得到的下标值如上图,数组长度为15的下标都为8,这样就会造成不同的key,存放在同一个链表中,造成碰撞的几率增大,如果查询的时候还需要循环这个链表,造成查询慢。
还有一个问题,就是末位为零,进行与运算,得到的结果是末位永远没有1,这样就会造成某些下标无用,消耗了table的空间。
真正创建新节点
|
|
它会先获得链表中的头节点,然后将新节点放进链表头部,旧节点放在新节点后面。
数组扩容问题
|
|
插入新值的时候,计算极限容量是否已经到达,如果达到了,就调用上面的方法进行扩容,将桶容量增大到两倍。
HashMap的get(K)
|
|
真正调用的方法:
get获取实现比较简单,就是计算出key键的hash值,找到在数组中对应的链表位置,然后循环链表,比较key是否一致。
为什么HashMap是无序的
下面是HashMap的迭代器实现:
从上面的代码可以看出,遍历HashMap,都是根据链表的index从上往下进行遍历,由于HashMap的存储规则,后来新加的值有可能在链表的头部,所以遍历HashMap是无序的。
HashMap不是线程安全的
因为看到有modCount这个字段,查询了资料,发现这个代表这修改次数,对HashMap内容修改都将增加这个值,在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount,在迭代过程中,判断modCount跟expectedModCount是否相等,如果不相等,表示已经有其它线程需改了Map。
有个同步机制:
如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。